A story of Default wordlist in Dirsearch to 20k INR Bounty
Introduction
Hi folks , I hope so Every is doing good . One Mid afternoon in the work , I got some time to work on bugbounty . I usually don’t work on any platforms like hackerone , Intigriti or Bugcrowd . I always hunt using a Google dorking and I found a target with good scope and able to test broad functionality but there is twist out there . I don’t whether they respond or not . Some companies host a bugbounty program but usually they don’t respond . Usually in this case , I don’t completely engage me into the target . At first I will submit the low hanging bugs and wait for the response from the particular team
So , At first I gone through their Bugbounty policy as they mentioned everything under the wildcard *.example.com is in the scope . So, Without wasting the time . I started with the subdomain enumeration using subfinder , amass , assetfinder , crobat , github-subdomains , findomain and Subdomain bruteforcing using puredns with combination of both the jhaddix all.txt and Asssetnote best-dns-wordlist and Subdomain alteration with DNSCewl and puredns to resolve the file
Recon flow
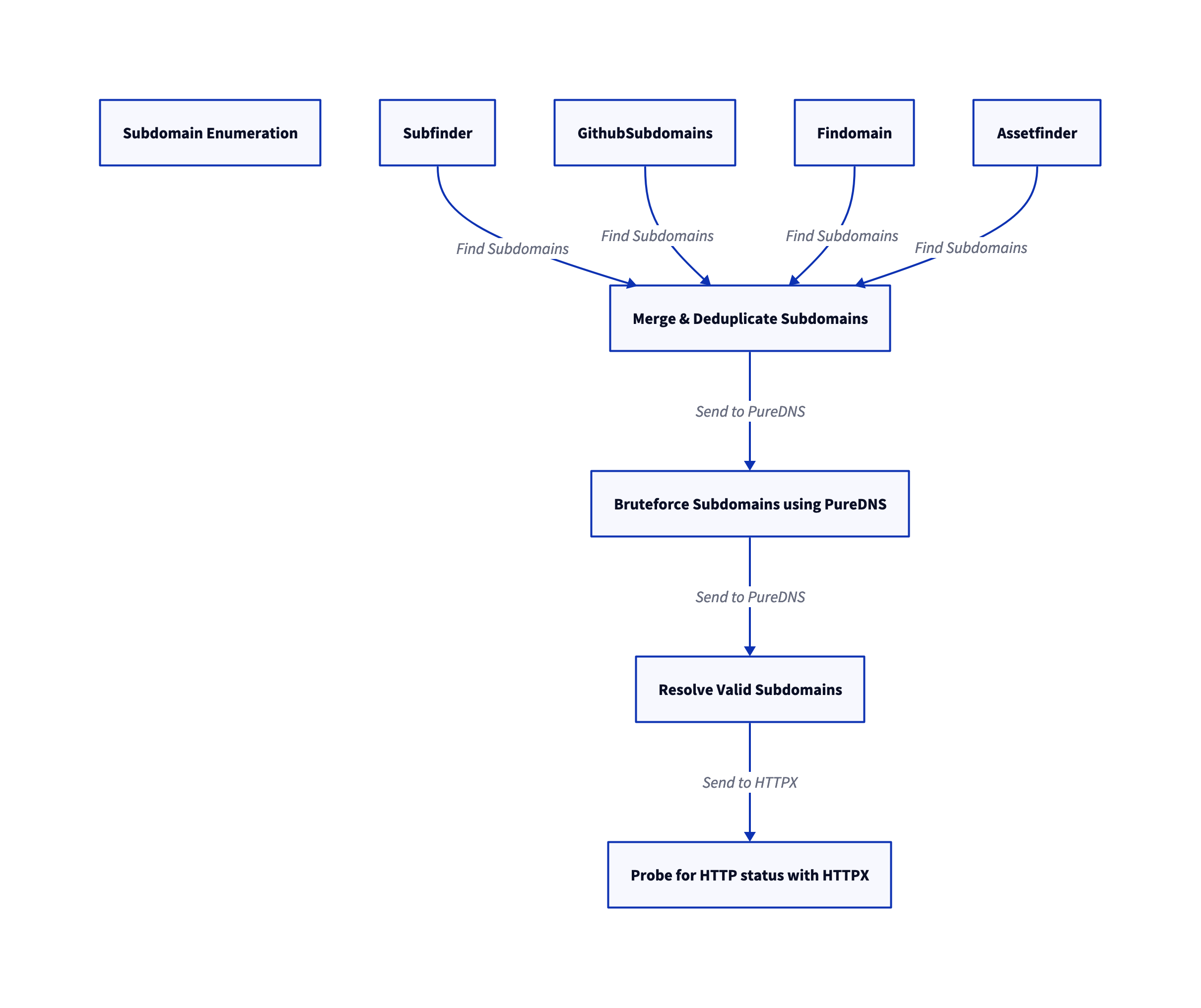
After Recon
Then, using the same httpx we can do many things. Like looking for the status codes and titles. But it doesn’t seem to be any interesting.
Then I started the directory Bruteforce using dirsearch on 404, 403 pages. Here there are some results but most of them false positives. On the other hand in the screen command, I started the nuclei for the list of probed domains aside But After Analyzing the result from nuclei . There is no high , low , medium , critical vulnerabilities.
But in info , the subdomain has a hidden ec2 instances In other Words , Nuclei detects as EC2 detection . So, At first I thought it was a false positive later on I manually inspected the source code and I found that EC2 instances were there in the source code
When Visiting the Hidden EC2 instances from the source code , It gave me 403 Forbidden.
Enumerate the 403: Guess What?
Ever stumbled upon a 403 Forbidden or 404 Not Found error while browsing a webpage? It’s frustrating, right? But for a security enthusiast, these errors can be intriguing entry points. One common approach I use to investigate further is Directory Fuzzing—and in this case, I used Dirsearch, a popular tool for directory enumeration.
Step 1: Fuzzing the Target Directory
I started by running the following Dirsearch command:
dirsearch -e conf,config,bak,backup,swp,old,db,sql,asp,aspx,py,rb,php,tar,log,txt,json,xml,zip -u https://target
This command scans the target URL with a wide range of file extensions such as conf, bak, sql, php, json, and more, which are commonly exposed by misconfiguration.
Interestingly, Dirsearch hit upon a 200 OK response for the /app directory, but when I visited the URL directly, it gave me a blank page. Not giving up, I decided to go deeper and launched another round of Dirsearch on the discovered /app path.
Step 2: Digging Deeper
Now, I updated my Dirsearch scan to focus on the /app directory:
dirsearch -e conf,config,bak,backup,swp,old,db,sql,asp,aspx,py,rb,php,tar,log,txt,json,xml,zip -u https://target/app
This time, I struck gold: /app/customer.csv was discovered. Upon visiting the URL, the file was downloaded to my system.
Step 3: Jackpot! Sensitive Data Found
Opening the customer.csv file revealed something that should never be publicly accessible—Personal Identifiable Information (PII), including user credentials, credit card details, and other sensitive customer information.
Conclusion
On 02/10/2021, I reported this issue to the program, and by 03/10/2021, the bug was accepted. Just a day later, on 04/10/2021, the team rewarded me with 20k INR for the find.
As a tip for anyone exploring directory fuzzing: Don’t stop at one path, especially if it gives a blank or ambiguous response. Always go deeper—fuzz the blank page—you might uncover sensitive data or even more valuable information. Persistence is key in uncovering hidden vulnerabilities!